题记:
这是我的第一篇技术博文,写得不好请多提意见。然后,感谢张志斌老师,毕业之前张老师帮助我解一些“神奇的bug”,现在毕业一个月,我终于自己开始解自己认为“神奇的bug”。
背景:
我需要在spark streaming上做一个窗口的统计功能,但是因为一些原因,不能利用window相关算子。于是,我在driver上保持了一个resultRDD,在DStream内不断地去更新这个resultRDD,包括新信息的统计,和过期信息的剔除。
现象:
batchSize设置为1分钟,程序刚开始运行的一天内,每个batch的处理时间都是2秒以下,如下图: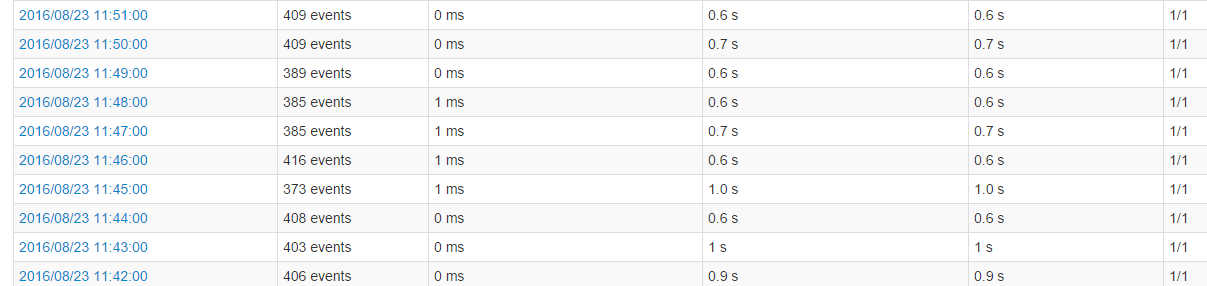
运行长时间之后,监控页面如下:(忽略时间戳,为了截图重启了程序)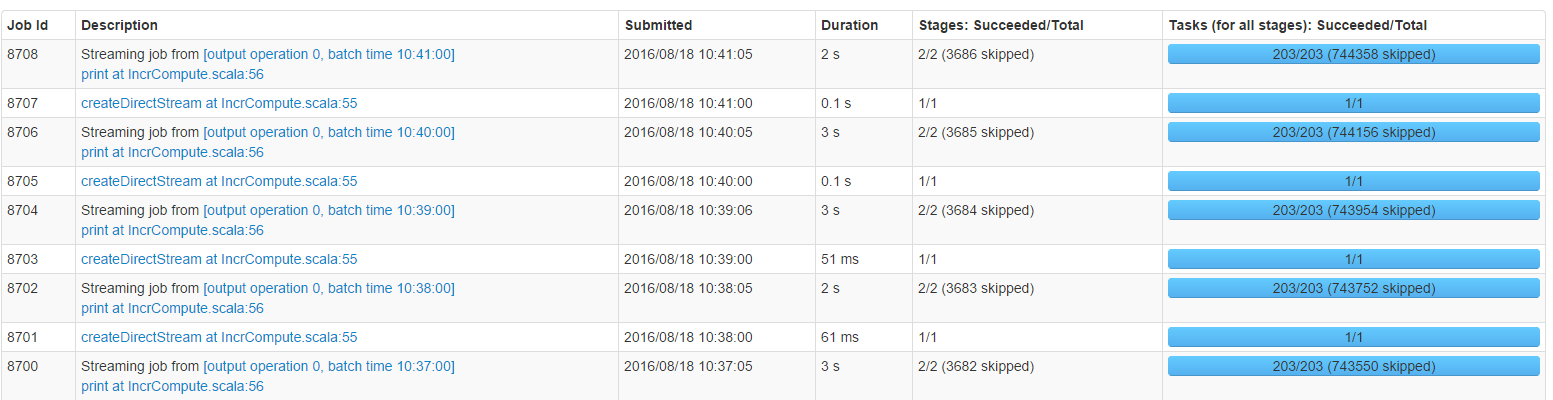
可以看到,每个job都skip了大量的stage,每个stage内,都skip了大量的task。而且有一个很有意思的现象,skip的数量都是递增的。而且,从skip的数字上来看,也很有规律。
再注意 job内stage的执行时间,每个job有2个stage,加起来平均2~3秒。但此时,batch的处理时延已经达到了20~30秒。
总结一下遇到的问题:我的streaming程序连续运行一周之后,慢了一个数量级,但实际花费在执行上的时间近似不变。到这,我已经认为是一个“神奇的bug”了。
debug:
严格的说,batch的处理时间 = 生成执行计划时间 + task调度时间 + 各个stage执行时间
在我的场景中,batch的处理时间远高于stage执行时间和。就说明,执行计划生成和task调度花费了大量时间。task调度是yarn负责,开销主要在分发策略和网络开销上,这部分不会太耗时。剩下就是执行计划生成了。
在spark中,执行计划是通过RDD的依赖关系来生成DAG,并以此来划分stage生成执行计划,代码就不贴了,大致就是根据RDD的依赖关系递归地深度优先搜索,终止条件就是某个RDD的依赖为空,也就是说搜索到源RDD。
了解了DAG的生成原理之后,再回过头来看文章开头说的背景,我们来模拟一下DAG的生成,DStream.foreachRDD,开始计算,假设当前时间为 t,然后t时刻的resultRDD依赖t-1时刻的resultRDD,t-1时刻resultRDD依赖于t-2时刻的resultRDD。。
问题的根源找出来了,随着时间的推移,依赖的层次越来越多。最终导致DAG的生成耗费了大量时间。
要解决这个问题,就要清除掉resultRDD的依赖关系,如何清除?
答案是 checkpoint
在checkpoint之后,spark会清空rdd的依赖。
至此,“神奇的bug”解决。
至于前面提到的大量skip:DAG生成遍历了rdd的整个历史,但是在DAG具体的执行过程中,会发现某一些stage,task已经被运算过,因此不会再次计算,这样就产生了skip。
最后,愿我的未来再不会觉得有“神奇的bug”。